Swarm architecture — a view from above
Edit-1: The blog post in the in-depth architecture series about Swarm-DPA (chunker) is available now.
Edit-2: The blog post about Swarm Transport layer and Services is available now.
In this post, I’ll discuss the basic modules that make up a Swarm node and its architecture.
What is Swarm and why use it?
Swarm is an open, neutral, borderless, censorship-resistant storage and communication infrastructure. A bit more specific, it’s a decentralised network of nodes that can store and exchange data. It’s neatly summed up in a quote by one of the lead developers of Swarm: “If Ethereum is the world’s computer, then Swarm is the world’s hard disk”.
Every application could benefit from using it and in doing so decrease reliance on central servers, reduce the risk of attacks and downtime, while increasing redundancy, security and privacy.
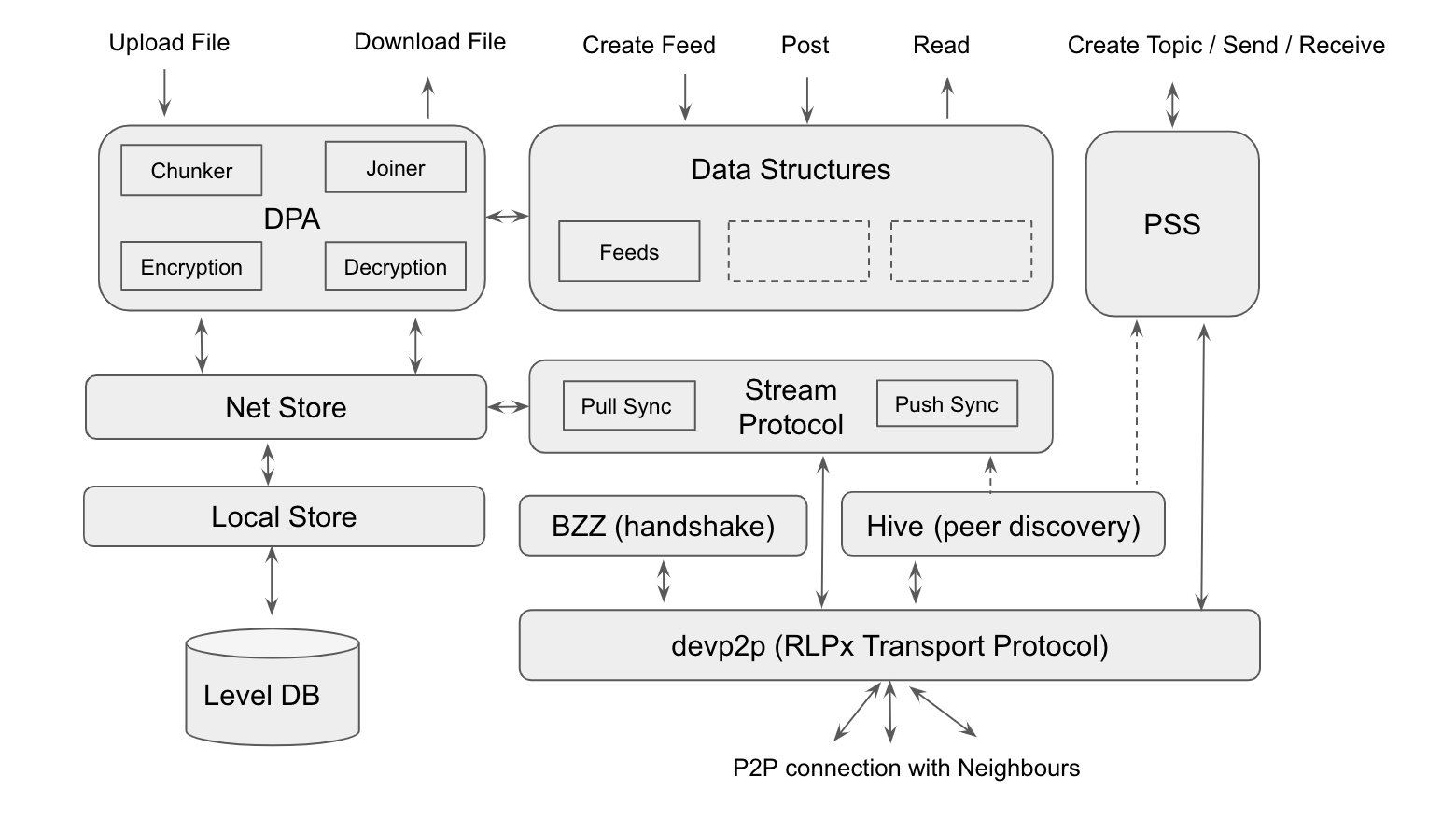
In the text below, I describe the basic modules that make up a Swarm node and their architecture to help readers better understand how the network works and what the nodes do.
The building blocks of a Swarm node
1) Devp2p/RLPx Transport Protocol
A Swarm node does not connect to a single centralised server. Instead, it connects to other Swarm nodes called peers, which are close by. Communication and connection to any other Swarm node in the network takes place indirectly through peers. As we can see in the picture above, Swarm uses devp2p, the peer-to-peer layer of Ethereum, as the base for nodes to connect to all of their neighbours.
Devp2p itself employs the RLPx transport protocol, which uses a Diffie –Hellman** **key exchange algorithm to establish an encrypted communication channel with each of the neighbours. Once a devp2p connection is established, many protocols can be multiplexed on top of this. At present, the Swarm runs protocols like BZZ-handshake, Hive discovery and stream protocols on top of devp2p. To learn more about RLPx, please click here.
2) Swarm Overlay Kademlia — Hive
If we look one step above devp2p, we can see that Swarm uses Hive discovery protocol.
Hive is used to find peers based on the information they advertise on the network. Swarm then uses Hive to build and maintain a Kademlia table which is nothing but a list of peers grouped according to their distance (that’s the count of same MSB in the nodes’ IDs). These peers act as intermediary points through which a particular Swarm node can communicate with the rest of the network. If any of the peers goes down, or if a new closer peer is found, the list is updated.
Swarm uses a slightly modified version of Kademlia called “Forwarding Kademlia” to build its overlay network neighbourhood.
3) BZZ
BZZ is a Swarm-specific handshake between Swarm peers. Once a peer is discovered in Hive, it negotiates the handshake with that peer. In a later version of Swarm, BZZ might get replaced with devp2p specific method called ENR.
Swarm has many protocols (Sync/Stream protocol, PSS and several upcoming other protocols) that run on top of devp2p. These protocols have specific functions like syncing chunks across the network neighbourhood, sending communication messages across the network etc. Hive serves as a “Peer Information Store” for these Swarm’s protocols.
4) Stream Protocol
Stream protocol is responsible for distributing chunks across the network. Syncing is the process of sending chunks (created during a file upload) to destination nodes for storage. Streamer (or Pull Sync) is the current protocol in action and there is also work in progress to improve syncing using Push Sync. These protocols are instantiated on top of devp2p for every peer that is connected. Swarm nodes continuously keep in touch with their peers to share the chunks belonging to their neighbourhood, based on chunks’ addresses.
5) Postal Service over Swarm (PSS)
PSS is the communication infrastructure provided by Swarm. It is similar to Whisper in gossiping a message at a certain address space, but with more tuneable security guarantees. The Hive-based routing that the Sync protocol uses can be used to send not only chunks but messages too. PSS does exactly that.
It also offers a concept of Topics. A topic can be created by a PSS node and other nodes can opt-in to listen in on the topic. The message sent to a topic will be received only by the members who are subscribed to that topic. Apart from that, it takes care of secure key exchange using Diffie –Hellman for encrypted communication. PSS is a very useful infrastructure which can be used by an application to communicate safely and in a decentralised manner.
6) Data Structures — Feeds
Feeds is the first data structure in Swarm. It is like a key-value (KV) value store, where the value part can only be written by the owner and accessed by others. A Feed is like a single instance of the key-value in a KV store. Once a feed is created, the owner can post updates to the value. Feed stores the historical updates and by default serves the latest value when retrieved. A user can create as much feeds as required. This is the first data structure that made managing mutable content in Swarm a breeze.
7) Distributed PreImage Archive (DPA)
DPA functions as an interface between the external world and the Swarm network. When a file is uploaded, DPA splits the files into pieces (chunker), encrypts them and stores them in the local data base. Later, it triggers the syncing protocol to transport these new chunks to their respective destinations in the Swarm network.
The pyramid chunker is the current implementation of chunker in Swarm. It splits the file into 4 kb pieces called chunks and creates a Merkle tree out of it. The leaf nodes of the Merkle tree are the data chunks and the rest of the chunks are tree chunks. The root hash of the Merkle root is the Swarm hash for that file. These chunks are then optionally encrypted and stored in the local LevelDB from where the chunks are synced to the network.
Similarly, the opposite happens when a file is requested from the Swarm network by supplying its hash. DPA picks the chunks belonging to the file, optionally decrypts and stitches them to form the original file.
8) Storage
Chunks are stored locally in every Swarm node. When a file is uploaded locally, those chunks are stored in the local store. The Net store then triggers the sync protocol and pushes these chunks in the Swarm Network. Similarly, the other Swarm nodes send chunks that belong to this neighbourhood to get stored.
Local store is the storage layer in Swarm. This uses a LevelDB database to store the chunks. This layer knows nothing about the files. All it deals are in chunks. By default, five million chunks can be stored in the local store. Garbage collection kicks in when more chunks are stored. GC keeps the most recent chunks and deletes the oldest ones.
What next
The above described concepts are the major modules in Swarm. In the coming weeks, I will start writing in detail about each module, one at a time. Swarm development is at the fastest pace now and I will try to add proposed changes here and there as well. Stay tuned!
*Thanks to **Fabio Barone **and *_Elad Nachmias _of the Swarm team for reviewing the architecture diagram and the blog.
Note: This blog was updated on 31.Dec. 2019.