Swarm on WASM — SWASM

In this technical blog we’ll look at how we can use pieces of Swarm code and turn them into functional modules that can work within a web browser. By making these web browser-based, resource-light modules we can exclude Web 2.0 ways of communicating with the Swarm network and use Swarm’s native methods instead. This way, we can begin using the Web in a truly decentralized manner but without the clonky user experience and jumpstart adoption rates of decentralized technologies.
We see enabling a wider use of Swarm and consequently of a **zero-data approach **to using the Web as strongly aligned with Fair Data Society’s mission and values. That’s why we have decided to include this blog post in our publication.
Dapps over Swarm
Today, Web 3.0 dapps can already store user data, user state or the dapp code itself in Swarm. The issue that arises here is that many of them are still using Web 2.0 methods (like http or https connections) to connect to a central Swarm gateway. It is similar to how Ethereum dapps use Infura to access the blockchain.
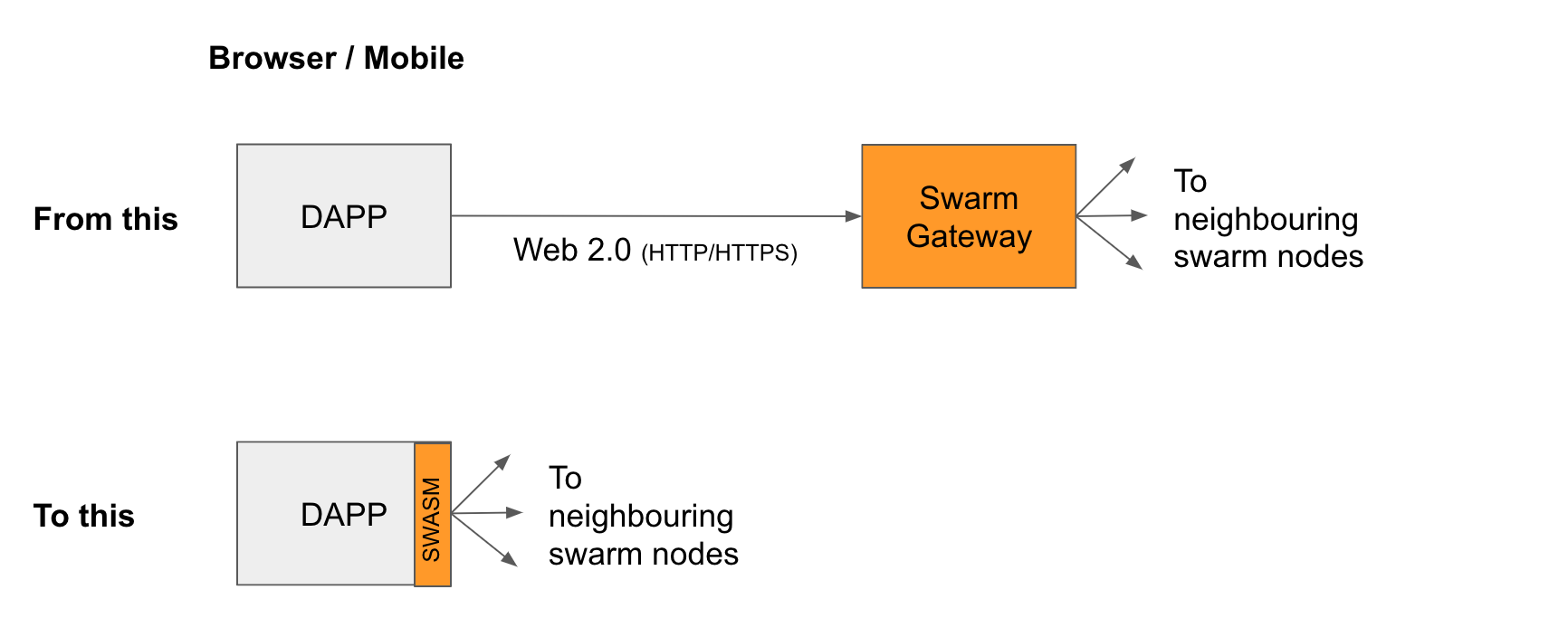
Fortunately, there is a better way to enable dapps to use Swarm in a more decentralized manner. One way to achieve this is to rewrite Swarm in a web-client-friendly languages likes JavaScript. Another way is to wrap the Swarm code in WebAssembly (WASM), so that it can be used on the client side. These methods get rid of the last mile Web 2.0 access and help dapps to become truly decentralized in nature.
SWASM: Swarm on WebAssembly
Compiling the entire Swarm code as one monolithic WASM module wouldn’t make sense as it would result in a large binary size and add delay to front-end apps. Instead, we can split Swarm into multiple logical components and have a WASM wrapping for each of them. This will allow the front-end dapps to pick and choose the modules they need, reducing unnecessary bloat in the code.
Pushing Swarm to client side also means we should be light on storage and bandwidth requirements. The Swarm team has already published a GitHub track on **Swarm Light Client**. It is recommended that we implement changes from the track into SWASM modules that we are proposing below. The following are some of the SWASM modules that are required to achieve a truly decentralized Swarm access and use.
1) Swarm Network Layer WASM
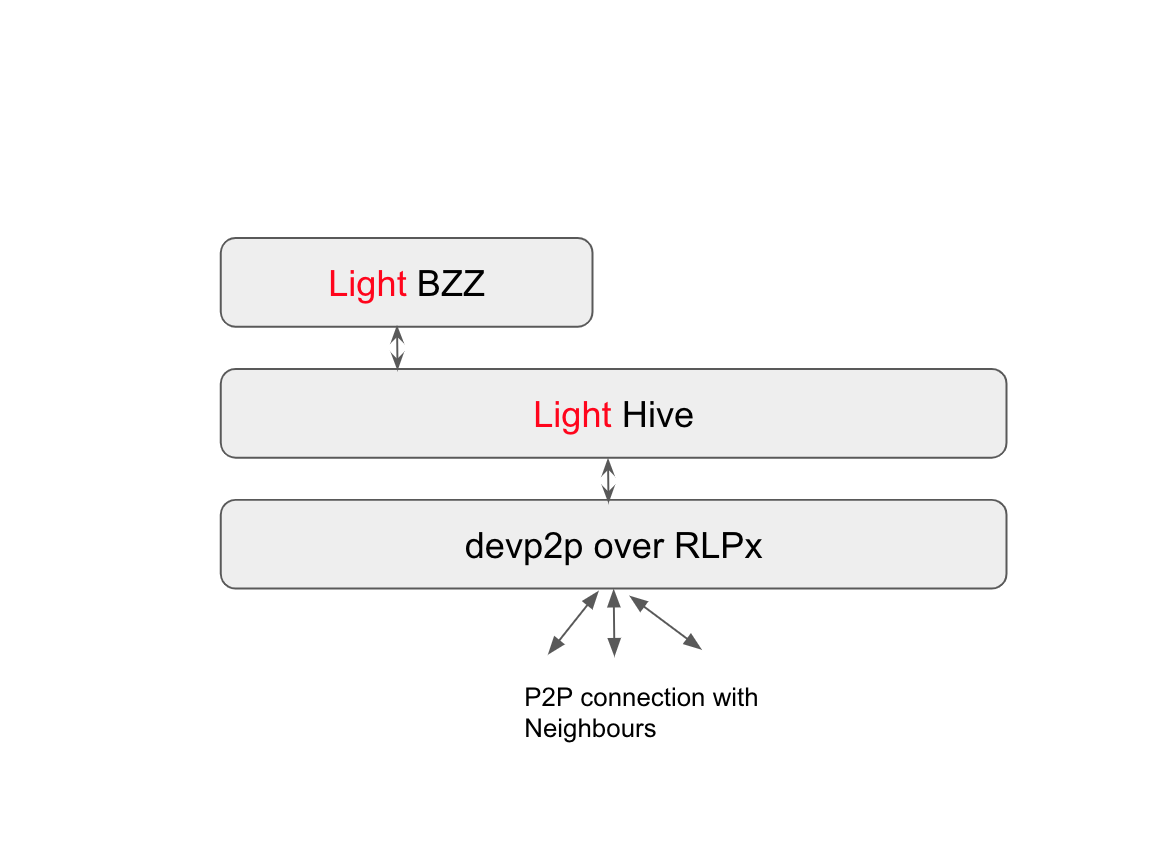
BZZ is the main Swarm protocol which takes care of syncing the chunks across the network. The Swarm overlay kademlia, or Hive as it’s called in Swarm code, is the one responsible for routing packets in the Swarm network. This overlay depends on the lower level devp2p protocol to maintain an encrypted channel to each of the peers of a given Swarm node.
Hive is the entry point to the Swarm world. If this layer is packaged as a separate WASM module, it can be used by any dapp to communicate natively with any Swarm node. The input of this module will come from either the Distributed Pre-Image Archive or the Postal Service over Swarm WASM modules described below. The output of this module will be sent to the Swarm network, natively, from the dapp itself.
2) Distributed Pre-Image Archive (DPA) WASM
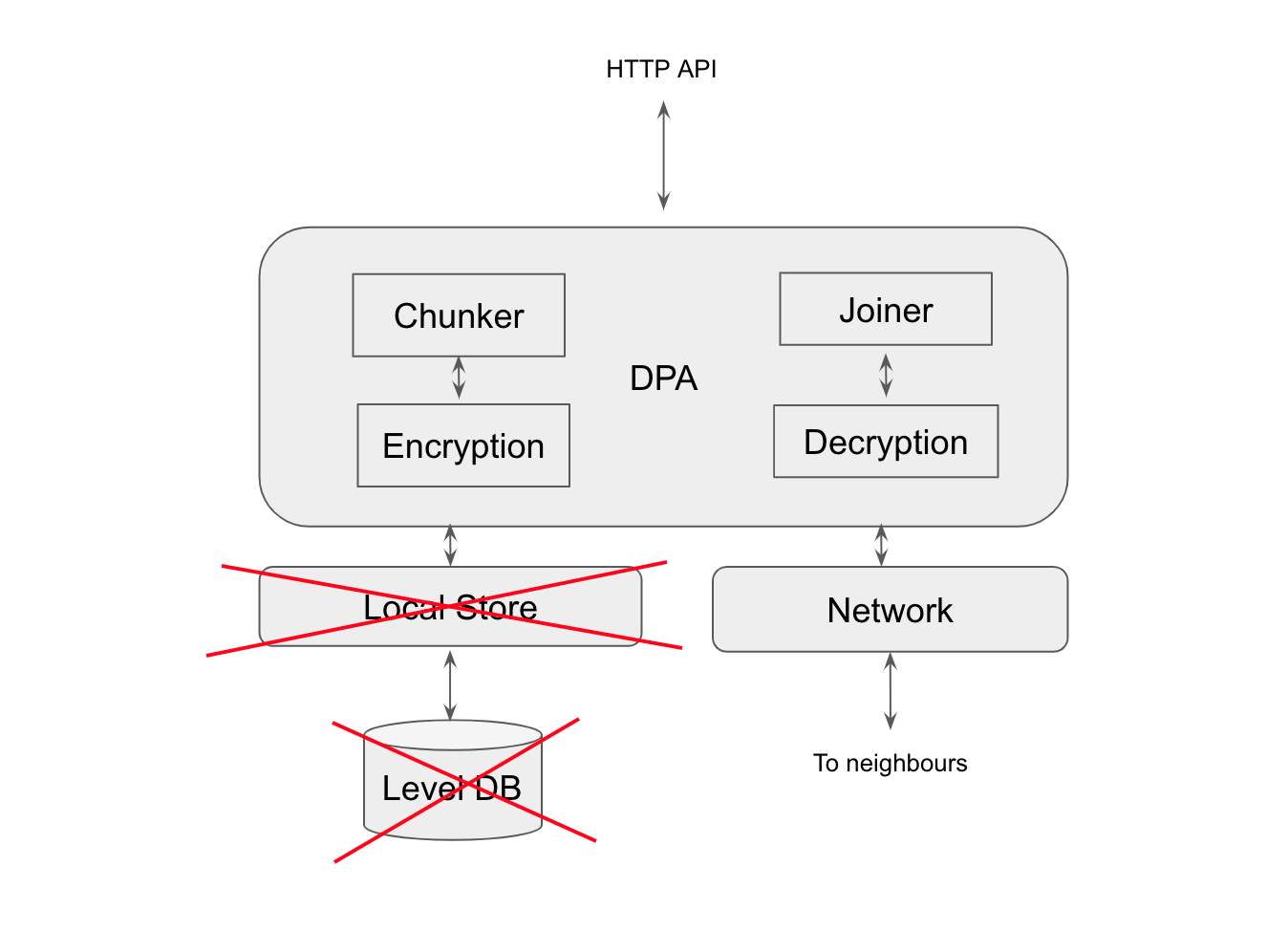
DPA takes care of the functions like chunking files to smaller pieces and encryption. This functionality is needed only for dapps which need to upload files to Swarm. In a full Swarm node the DPA also has a local store, which stores the chunks close to this node. But for most of the client-side functions, the DPA should implement light storage as recommended in the **Swarm Light Client** proposal. This WASM module should be included in dapps that require the storing of user data or user state in Swarm. If a dapp decides to to use this WASM module, the module’s input should come from the dapp and then send the encrypted chunks to the first — Swarm Network Layer WASM — module.
3) Postal Service over Swarm (PSS) WASM
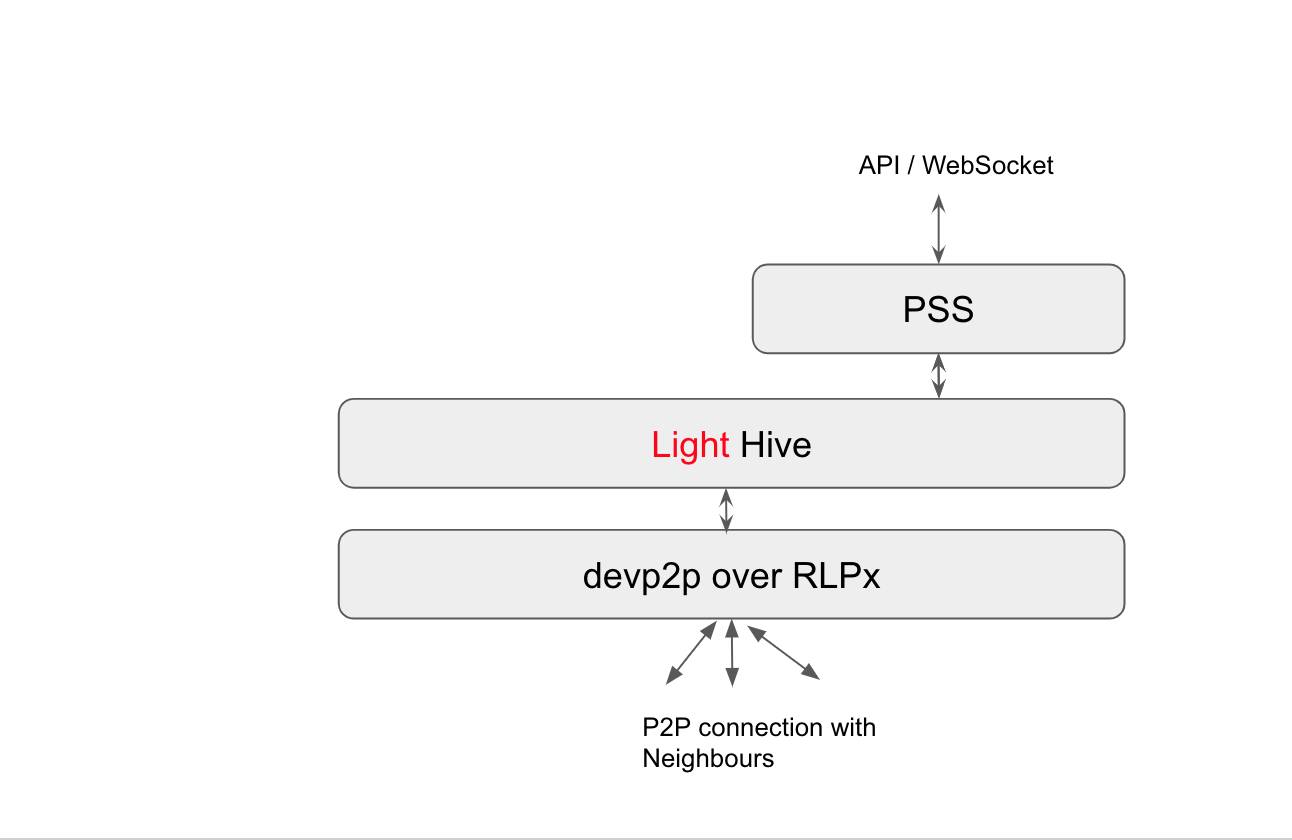
Postal Service over Swarm is Swarm’s communication module. Dapps which need a decentralized, censorship-resistant way to communicate between themselves are the prime users of this module. For example: chat applications. PSS uses Swarm kademlia routing to find the destination of the message. It also takes care of encryption and key management.
PSS takes the input from the dapp and gives the output to the Swarm Network Layer WASM module, which in turn sends the message using the kademlia routing.
4) Feeds WASM
Feeds is a simple data structure over Swarm for dapps to store mutable data in Swarm. Feeds is a simple mechanism for the network to remember the latest hash of the data in question. Feeds take the input from the dapps and use the DPA layer to store the details in Swarm. This WASM module will be useful for dapps that needs some sort of mutability in storing data in Swarm.
Supporting Functionalities
1) Compression
Lossless compression is something which is currently not supported by Swarm. If implemented, it should be a part of the DPA module described above. There are a couple of things that need to be taken care of when implementing compression in Swarm, though:
- We have to be careful when using block compression like snappy, bz2 etc. These block compression schemes can uncompress a portion of file without accessing the entire file. This is important, as the files in Swarm is split in chunks and scattered around the network.
- There should be some index which maps the actual location of a file to the compressed location. Because Swarm chunking works on actual file locations, we should be careful not to disturb this logic.
2) Blocks
The chunks in Swarm are 4 kb in size and the size is fixed. For some use cases, like video streaming, this is a very nice property. But for many applications which handle large amounts of data (e.g. analytics, big data processing, ETL…), keeping track of millions of chunks is an overhead.
Block is an abstract way of thinking about chunks. Several chunks form a block. The size of the block is fixed for a single file, which is decided during the file creation in Swarm. Unlike chunks, the block metadata is exposed to the application. Applications can perform their logic on a per block basis.
The file metadata will have details about the blocks, like encryption key, compression scheme etc.
Making a better and more private Web for all
The development of these four modules is an important step for the adoption of decentralized technologies and it will benefit the whole Swarm ecosystem. The modules will give dapps a direct and decentralized way to communicate with the Swarm network through established interfaces such as a web browser, creating a bridge between Web 2.0 and Web 3.0.
That’s why Datafund’s team have decided to make the development of these modules their next contribution to Fair Data Society and the modules have been included in our roadmap as well. We look forward tackling this challenge, creating a better and more private Web for everyone.